
- The Goal: Move from 'probabilistic guessing' to 'verified retrieval'.
- The Method: Comparing AI outputs against a structured, cited knowledge base.
- The Result: AI that knows when it doesn't know the answer.
Why AI Struggles with Truth
Most Large Language Models (LLMs) are basically high-tech autocomplete. They don't have a database of facts; they have a map of how words usually follow each other. If a model sees the phrase "The capital of France is...", it doesn't "look up" Paris in a file. It just knows that "Paris" is the most statistically likely word to come next. This creates a massive gap in reliability. When you ask about something obscure-say, a specific regulation in the 1920s shipping industry-the model might not have enough strong statistical patterns to rely on. Instead of saying "I don't know," it fills in the blanks with plausible-sounding nonsense. To fix this, we need fact-checking AI systems that can cross-reference their internal logic with external, verifiable data. If the AI says X, but the benchmark says Y, the system can flag the error before the user ever sees it.Wikipedia as the Perfect Yardstick
Why use Wikipedia instead of a random set of textbooks or a proprietary database? First, it's structured. Every claim on a well-maintained page is (ideally) backed by a citation. Second, it's an open standard. Researchers can download the entire dump of Wikipedia and use it to create massive datasets for testing. When developers use Wikipedia as a benchmark, they aren't just checking for a "correct" answer. They are checking for "grounding." Grounding is the process of linking an AI's response to a specific piece of source text. For example, if an AI claims that the Great Wall of China is 13,171 miles long, a grounded system will point directly to the Wikipedia sentence that confirms that number. If the AI provides a number not found in the text, the benchmark marks it as a hallucination. This transforms the AI from a storyteller into a research assistant.| Method | Source of Truth | Strength | Weakness |
|---|---|---|---|
| Internal Weights | Training Data | Fast, no external lag | High hallucination rate |
| RAG (Retrieval-Augmented Generation) | Dynamic Docs (e.g., Wikipedia) | High accuracy, citable | Slower, depends on source quality |
| Human Review | Expert Knowledge | Nuanced, deep context | Impossible to scale |
The Mechanics of RAG and Grounding
To actually use Wikipedia for fact-checking, developers often employ a technique called Retrieval-Augmented Generation (RAG). Instead of relying on the AI's memory, RAG works in a loop. First, the system takes the user's question and searches Wikipedia for the most relevant paragraphs. Then, it feeds those paragraphs into the AI along with the question, effectively saying, "Here is the truth; now answer the question using only this information." This drastically reduces the chance of the AI making things up. If the Wikipedia snippet doesn't contain the answer, the AI is instructed to say it doesn't know. This is a huge leap forward in safety. For instance, in a medical context, an AI using RAG might pull data from PubMed or specialized wikis to ensure that a dosage recommendation is backed by a real document rather than a statistical guess.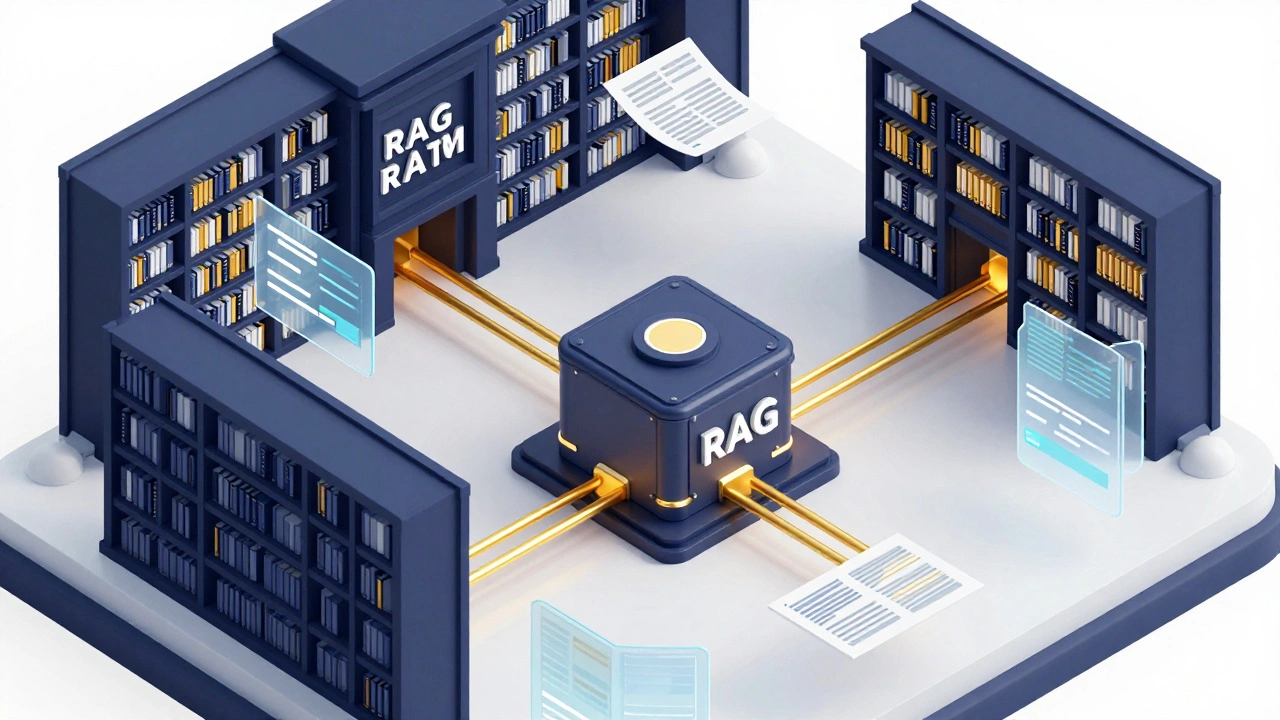
Building Knowledge Graphs for Better Accuracy
While raw text is helpful, the real power comes from turning Wikipedia into a Knowledge Graph. A knowledge graph doesn't just store sentences; it stores relationships. It sees "Paris" as an entity, "France" as an entity, and "is the capital of" as the relationship connecting them. By mapping Wikipedia's infoboxes-those neat little tables on the right side of every page-into a graph, AI can perform "triplet verification." A triplet is a simple Subject-Predicate-Object statement (e.g., "Elon Musk [is CEO of] Tesla"). When an AI generates a claim, the fact-checker breaks that claim into triplets and checks if those specific connections exist in the knowledge graph. If the graph says the relationship is false or non-existent, the AI's claim is rejected. This is much more precise than searching for keywords in a paragraph.The Pitfalls: When the Benchmark Fails
Wikipedia is great, but it isn't a magic bullet. The biggest issue is "edit wars" and bias. If two groups are fighting over a political definition on a page, the "truth" in the benchmark might change from hour to hour. An AI trained to trust Wikipedia blindly might mirror those biases or report a factual error if the page is currently being vandalized. Another problem is the "long tail" of knowledge. Wikipedia is vast, but it doesn't cover everything. If you're asking about a very specific legal precedent in a small town in Nebraska, Wikipedia probably doesn't have the answer. When the benchmark is empty, the AI often reverts to its old habits of guessing. This is why the next step in AI evolution is "multi-source verification," where the system checks Wikipedia, then cross-references it with official government archives or peer-reviewed journals.
Practical Steps for Testing AI Accuracy
If you're a developer or a curious user wanting to test an AI's factual reliability, you can use a simple "verification loop" method. Don't just ask a question; ask the AI to prove it.- The Prompt: Ask your question but add, "Provide the exact quote from Wikipedia that supports this answer."
- The Audit: Take that quote and search for it on the actual Wikipedia site.
- The Gap Analysis: If the AI provides a quote that doesn't exist (a "fake quote"), you've identified a high-level hallucination.
- The Correction: Feed the correct Wikipedia text back into the AI and ask it to rewrite the answer based only on that text.
The Future of Verifiable Intelligence
We are moving toward a world where "Truth-Aware AI" is the standard. We won't just have one big model; we'll have an orchestrator that knows which benchmark to use for different topics. For history and general facts, it'll hit Wikipedia. For live financial data, it'll hit the Bloomberg Terminal. For coding, it'll hit GitHub documentation. This hybrid approach-combining the creative power of LLMs with the rigid accuracy of a benchmark-solves the biggest problem in AI: trust. Once we can prove that an AI is grounding its answers in reality, we can use it for high-stakes tasks like legal drafting, medical research, and scientific discovery without fearing a hallucinated footnote could ruin everything.What exactly is an AI hallucination?
A hallucination occurs when a Large Language Model generates text that is grammatically correct and confident but factually incorrect. This happens because the AI is predicting the next most likely word based on patterns, not retrieving a fact from a database.
Can Wikipedia be trusted as a sole source of truth?
While Wikipedia is highly accurate for general and historical facts due to its massive community of editors, it can suffer from bias or temporary vandalism. It is best used as a primary benchmark that is then cross-referenced with primary sources like academic journals or official records.
How does RAG differ from standard AI training?
Standard training involves baking information into the model's weights during a massive pre-training phase. RAG (Retrieval-Augmented Generation) allows the AI to look up fresh, external information in real-time, similar to how a human uses a reference book while writing an essay.
What is a Knowledge Graph and why is it better than text?
A Knowledge Graph organizes information as entities and relationships (nodes and edges) rather than strings of words. This allows AI to perform precise logical checks-like verifying if a person is actually the CEO of a company-rather than just searching for related keywords in a paragraph.
Will this stop AI from lying completely?
It significantly reduces the frequency of errors, but it doesn't eliminate them. The AI can still misinterpret the retrieved text or fail to find the correct document. However, it makes the errors transparent because the user can see exactly which source the AI used.
